Vulnerability Injection

Research in software security is hampered by a lack of ground truth datasets, without which it is difficult to compare techniques and measure fundamental quantities such as false positive and negative rates. To allow rigorous measurement of bug-finding performance and comparisons between different tools, we developed LAVA (Large-scale Automated Vulnerability Addition), a system that creates ground-truth vulnerability benchmarks data by automatically adding vulnerabilities to software and then measuring how many bugs are missed by bug-finders.
We have also used these vulnerabilities for defensive purposes by creating Chaff Bugs: large numbers of provably non-exploitable bugs that are added to software to deceive attackers into wasting valuable time and effort in an ultimately fruitless attempt to develop exploits for artificial bugs.
This project is a collaboration with MIT Lincoln Laboratory, Northeastern University, and Prof. Subhajit Roy (IIT Kanpur).
Software Security

Protecting software systems depends on understanding them. However, real-world software systems are large, opaque, and may lack source code or documentation. To help address the challenge of analyzing such systems, we built the Platform for Architecture-Neutral Dynamic Analysis (PANDA) in collaboration with MIT Lincoln Laboratory. PANDA extends the QEMU whole-system emulator to add key features that are vital to deep analyses: deterministic record and replay, which allows heavyweight whole-system analyses to be run offline without perturbing the execution of the system under test; whole-system dynamic taint analysis, to track the propagation of data throughout the system; and a flexible plugin system that allows new analyses to be rapidly prototyped in C/C++ (and, more recently, in Rust and Python).
In addition to creating tools for analyzing software, we have also built new techniques for vulnerability detection and mitigation, such as HeapExpo, a more precise use-after-free (UAF) detector that closes gaps in prior UAF defenses. Based on a sample of oss-fuzz vulnerabilities, we found that prior work would miss 10/19 UAF bugs due to register promotion. HeapExpo is open source.
Currently we are also working on techniques for fuzzing complex device driver code (such as drivers for WiFi peripherals), without relying on physical hardware.
Embedded Security

As the cost of microcontrollers has plummeted, embedded and “Internet of Things” devices have become ubiquitous. Despite their ubiquity, the limited computational resources (and the limited financial resources of the companies that make them) of these devices mean that they are often dangerously insecure. The MESS Lab is developing techniques to apply dynamic analyses, which examine software in vivo as it runs, to embedded firmware. This is challenging because scalable dynamic analysis depends on rehosting an embedded device inside an emulator. In collaboration with colleagues at Northeastern, EURECOM, VU Amsterdam, Boston University, and MIT LL, we recently systematized approaches to solving this rehosting problem and provided quantitative estimates of its difficulty.
Currently, we are also investigating techniques to reduce the attack surface exposed by embedded device drivers. To do so we automatically reverse engineer portions of embedded device firmware in order to identify unwanted hardware functionality and rewrite firmware to prevent potentially vulnerable driver code from being exposed to the outside world.
Machine Learning Security

In collaboration with Prof. Siddharth Garg’s EnSuRe group we have been investigating backdoors in deep neural networks and developing novel backdoor attacks as well as defenses against backdoors, such as fine-pruning and NNoculation. You can read more about this project on the EnSuRe Secure Machine Learning project page.
We have also recently been looking at the use of large language models to understand, transform, and produce code. Examples of code generation models include OpenAI’s Codex and GitHub Copilot, as well as the MESS Lab’s own GPT-CSRC model. GPT-CSRC powers https://doesnotexist.codes/, which challenges visitors to guess whether a snippet of code is real or auto-generated. With Prof. Ramesh Karri’s group we also performed the first systematic study of the security of code generated by Copilot.
In addition the security of ML models, we are also investigating applications of machine learning for security, including the use of language models to create retargetable decompilers that can transform assembly back into its original language and can be easily retrained to support new compiled languages like Rust, Go, OCampl, and Fortran.
Popular Paths
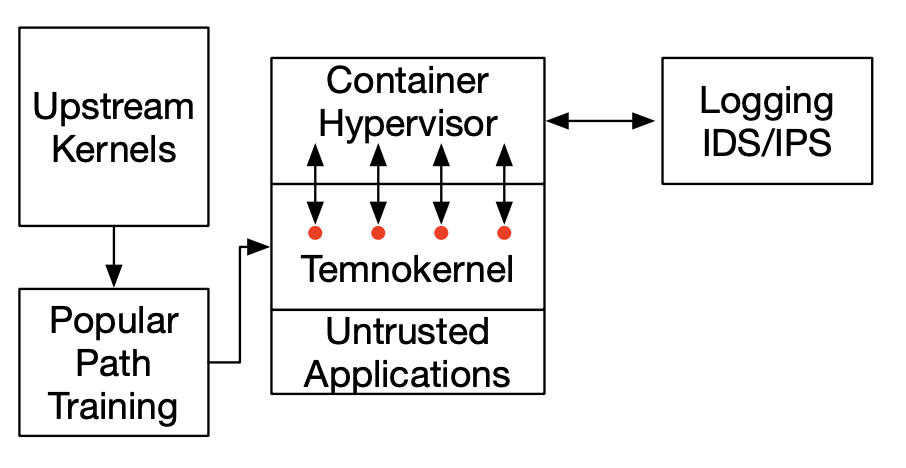
Operating system kernels are an especially important class of software, because they run at high privilege levels and must be resilient to malfeasance on the part of user-level processes. In collaboration with Prof. Justin Cappos’s SSL Lab we are building a new virtual machine design, Lind, based on the idea of restricting interactions with the kernel to only invoke commonly-used code. From our empirical observations, these “popular paths” are significantly less likely to contain vulnerabilities.
We are also using the idea of popular paths in a project called TRACKS to implement kernel exploit mitigations that target the kernel code that is most likely to be vulnerable. TRACKS is funded by a National Science Foundation Transition to Practice grant.
You can read more about this work at the NYU Secure Systems Lab.